Information exchange on the internet
Overview
Teaching: 25 min
Exercises: 0 minQuestions
What exactly is the internet?
How is information exchanged on the internet?
Why APIs?
Objectives
Understand how information is exchanged on the internet.
Key Points
The internet is a network of computers (servers) that exchange information with each other.
Various transport protocols, such as HTTP, dictate how information is transferred between servers.
Data is returned in various formats by servers, including
jsonandxml.APIs are exposed interfaces which allows us to programatically get data from the server.
The internet revolution
The roots of the internet can be traced back to the 1960s, when the U.S. Department of Defense developed ARPANET to ensure reliable communication. In the 1980s and early 1990s, key innovations such as TCP/IP protocols, the World Wide Web, and the first web browsers transformed the internet from a research tool into a global public network.
Since then, it has expanded at an extraordinary pace. The rise of personal computers, mobile devices, and broadband made it accessible to billions. Social media, e‑commerce, and cloud computing further deepened its role in everyday life, making digital connectivity indispensable.
Its impact on society has been profound: it has revolutionized communication, democratized access to knowledge, reshaped economies, and enabled new forms of work and collaboration. Today, the internet touches nearly every aspect of modern life — from banking transactions and healthcare to air traffic control, power grids, and telecommunications. The internet has also created a hyper-connected world, where connecting and engaging with others happens instantaneously and at scale. Information (and disinformation) has also become more readily available. It is impossible for us to imagine a world without the internet today.
At the same time, it poses challenges, including issues of privacy, misinformation, and unequal access. Still, the internet remains one of humanity’s greatest innovations — a force that continues to redefine how we connect, live, and progress.
The request life-cycle
Most of us associate the internet with a web browser like Chrome, Firefox, Safari — or even, God forbid, Internet Explorer. Yet what happens when you type www.google.com into the address bar is nothing short of an engineering marvel. The figure below shows how many things happen within the fraction of second once you hit enter.
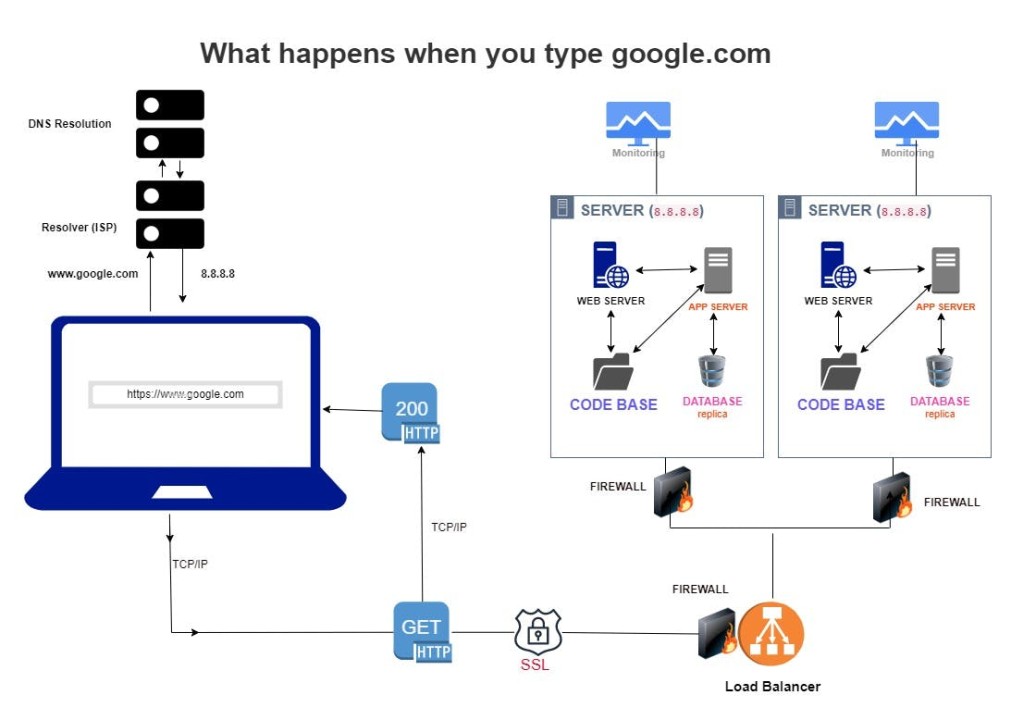
In reality, the internet does not understand human‑friendly names like www.google.com. Instead, every server on the internet is identified by an IP address — a unique series of numbers that acts like a digital street address. When you press Enter, your request first goes to the Domain Name System (DNS), which translates the web address into the correct IP address. Your computer then uses that IP to locate Google’s servers, establishing a connection through a series of routers and networks in milliseconds.
This process, though invisible to us, happens billions of times every day and is the backbone of the hyper‑connected world we live in. From streaming videos to sending money across the globe, it all depends on this seamless orchestration of networking technologies working in the background.
Data transfer over the internet
Various transport protocols have been developed to standardize how information is shared over the internet. Among the most common are http, https, and ftp. You’ve likely noticed these prefixes at the start of web addresses.
- HTTP (HyperText Transfer Protocol) is the foundation of data communication on the web, used to serve and display content like text, images, and videos.
- HTTPS is its secure counterpart, adding encryption via SSL/TLS to protect sensitive information such as passwords and payment details.
- FTP (File Transfer Protocol), while less common today, has traditionally been used for uploading and downloading files between computers and servers.
These protocols act like rulebooks, ensuring that no matter where you are in the world, your browser and the server you’re connecting to “speak the same language” and can reliably exchange information.
Recall that when we perform a search on the internet, we are sending data packets to the destination server. The various protocols have standardized how these packets are structured. We will dive more into how a http request looks like. This understanding will set us up to work with APIs (the chief outcome of this workshop).
How servers talk: the HTTP query and response structure
An HTTP request typically consists of:
- Method: The action to be performed (e.g., GET to retrieve data, POST to send data).
- URL: The resource being requested.
- Headers: Metadata providing additional context, like authentication tokens, content type, or caching instructions.
- Body (optional): Data sent to the server, usually with methods like POST or PUT.
HTTP methods
There are various methods defined in HTTP, including
GET,PUT,POST,PATCH,DELETE. Each of these methods correspond to an action that will be performed in the data exchange transaction. These actions also usually map to a specific endpoint in the API. Some of these methods and their actions are as follows:
- GET: Used to retrieve data from a specified resource. GET requests should be “safe” (not alter server state) and “idempotent” (multiple identical requests have the same effect as a single one).
- POST: Used to submit data to be processed to a specified resource, often resulting in a change of state or creation of a new resource on the server.
- PUT: Used to replace an existing resource with the provided data, or create a new resource if it doesn’t exist at the specified URI. PUT requests are idempotent.
- PATCH: Used to apply partial modifications to a resource, updating only specified fields rather than replacing the entire resource.
- DELETE: Used to request the removal of a specified resource from the server. DELETE requests are idempotent.
In the context of APIs, the most important methods that are exposed are
GETandPOST(understandably, since the other methods allow direct modification to the data! Imagine being able to use an API to delete the entire database of Uniqlo via a bad API call)
When the server has processed the query, it will respond with a response with the following components:
- Status code: Indicates the outcome of the search.
- Headers: Metadata about the response, such as content type or length.
- Body: The actual content — HTML, JSON, XML, or another format.
HTTP status codes
Most of us should be familar with the
404 - Page not foundstatus. However,404is not the only status code. Various status codes, corresponding to different outcomes, can be returned. The list below shows some of the most common (and important) codes.
Code Category Meaning 200 Success OK – request succeeded 301 Redirection Moved Permanently – resource has a new permanent URL 302 Redirection Found – resource temporarily resides at a different URL 401 Client Error Unauthorized – authentication required 403 Client Error Forbidden – request understood but not allowed 404 Client Error Not Found – resource doesn’t exist 408 Client Error Request Timeout – client took too long 429 Client Error Too Many Requests – rate limit exceeded 500 Server Error Internal Server Error – generic server issue 502 Server Error Bad Gateway – invalid response from upstream server 503 Server Error Service Unavailable – server overloaded or down 504 Server Error Gateway Timeout – upstream server failed to respond in time
APIs: the new economy
An understanding of the HTTP standard is helpful if we want to work with APIs. APIs (Application Programming Interfaces) are programmatic interfaces that allow different software systems to communicate with each other. On the web, most modern APIs are built on top of the HTTP protocol, meaning they use the same request–response structure as a web browser fetching a webpage.
Instead of returning HTML for a human to read, APIs typically return structured data (commonly JSON or XML) that applications can process. For example, a weather app might send an HTTP GET request to an API endpoint like:
https://api-open.data.gov.sg/v2/real-time/api/pm25?date=2025-01-01
The API then responds with a JSON object containing data such as:
{
"code": 0,
"data": {
"regionMetadata": [
{
"name": "west",
"labelLocation": {
"latitude": 1.35735,
"longitude": 103.7
}
},
{
"name": "east",
"labelLocation": {
"latitude": 1.35735,
"longitude": 103.94
}
},
{
"name": "central",
"labelLocation": {
"latitude": 1.35735,
"longitude": 103.82
}
},
{
"name": "south",
"labelLocation": {
"latitude": 1.29587,
"longitude": 103.82
}
},
{
"name": "north",
"labelLocation": {
"latitude": 1.41803,
"longitude": 103.82
}
}
],
"items": [
{
"date": "2025-07-29",
"updatedTimestamp": "2025-07-29T11:15:46+08:00",
"timestamp": "2025-07-29T11:00:00+08:00",
"readings": {
"pm25_one_hourly": {
"west": 22,
"east": 12,
"central": 18,
"south": 10,
"north": 16
}
}
}
]
},
"errorMsg": ""
}
By using standard HTTP methods (GET, POST, PUT, DELETE) and status codes, APIs provide a predictable and consistent way for developers to request, send, and manage data. This makes HTTP knowledge essential when building or consuming APIs, since every interaction boils down to crafting and interpreting these requests and responses.
Today, there are millions of APIs that are publicly available – some of which are free, while others require paid subscriptions. The emergence of Generative AI, which demands large volumes of data, has led to an explosion in the number of available APIs, with almost 10million APIs added in 2024 based on a survey at Postman. Being able to work with APIs is hence a critical skill in today’s digital economy.
Looking ahead
This concludes our primer on how the internet works and a brief introduction to APIs. We will now move on what everyone is here for – Python. In the next section, we will describe the motivation of this workshop to set the stage for the remaining of the workshop.